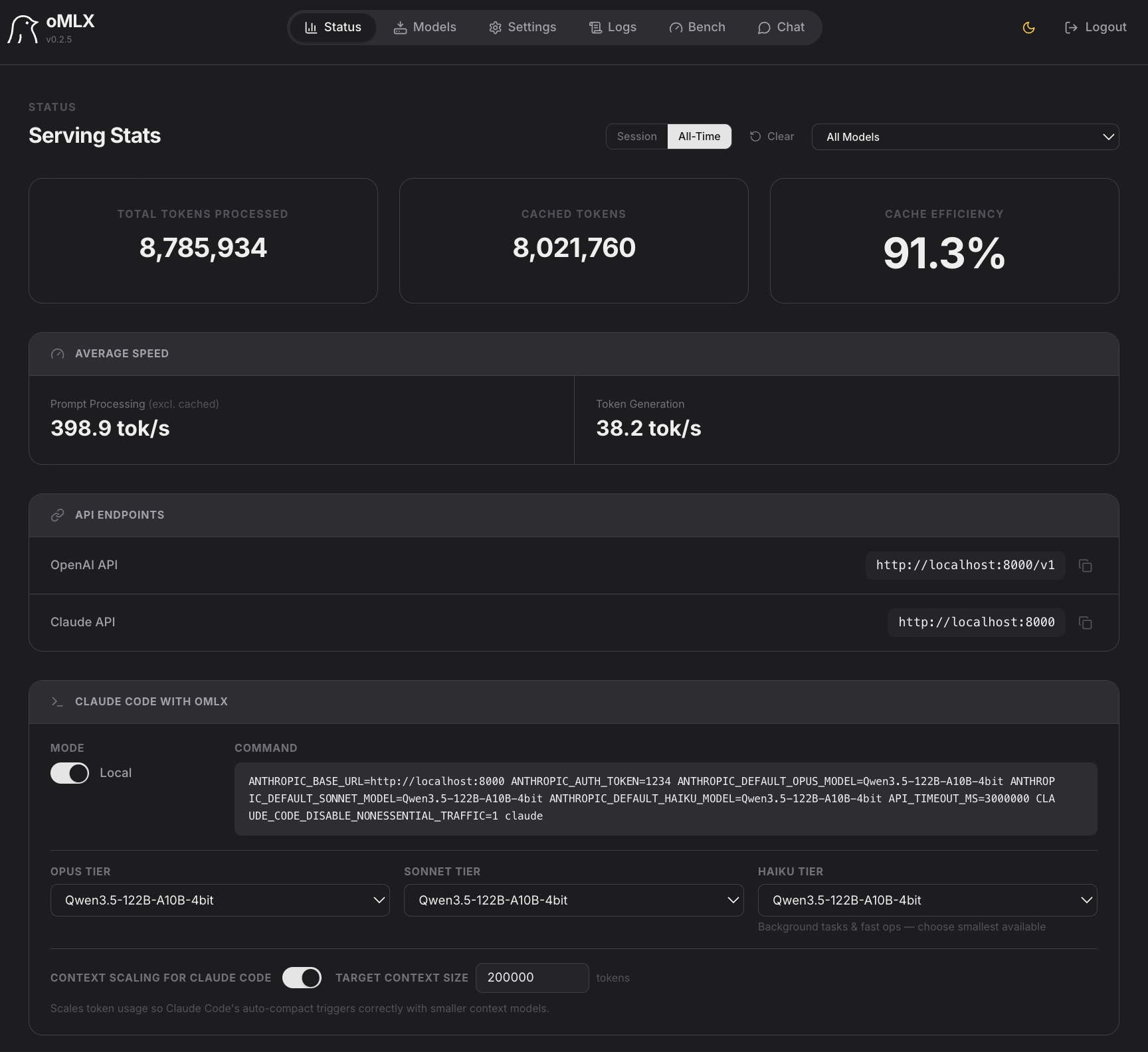
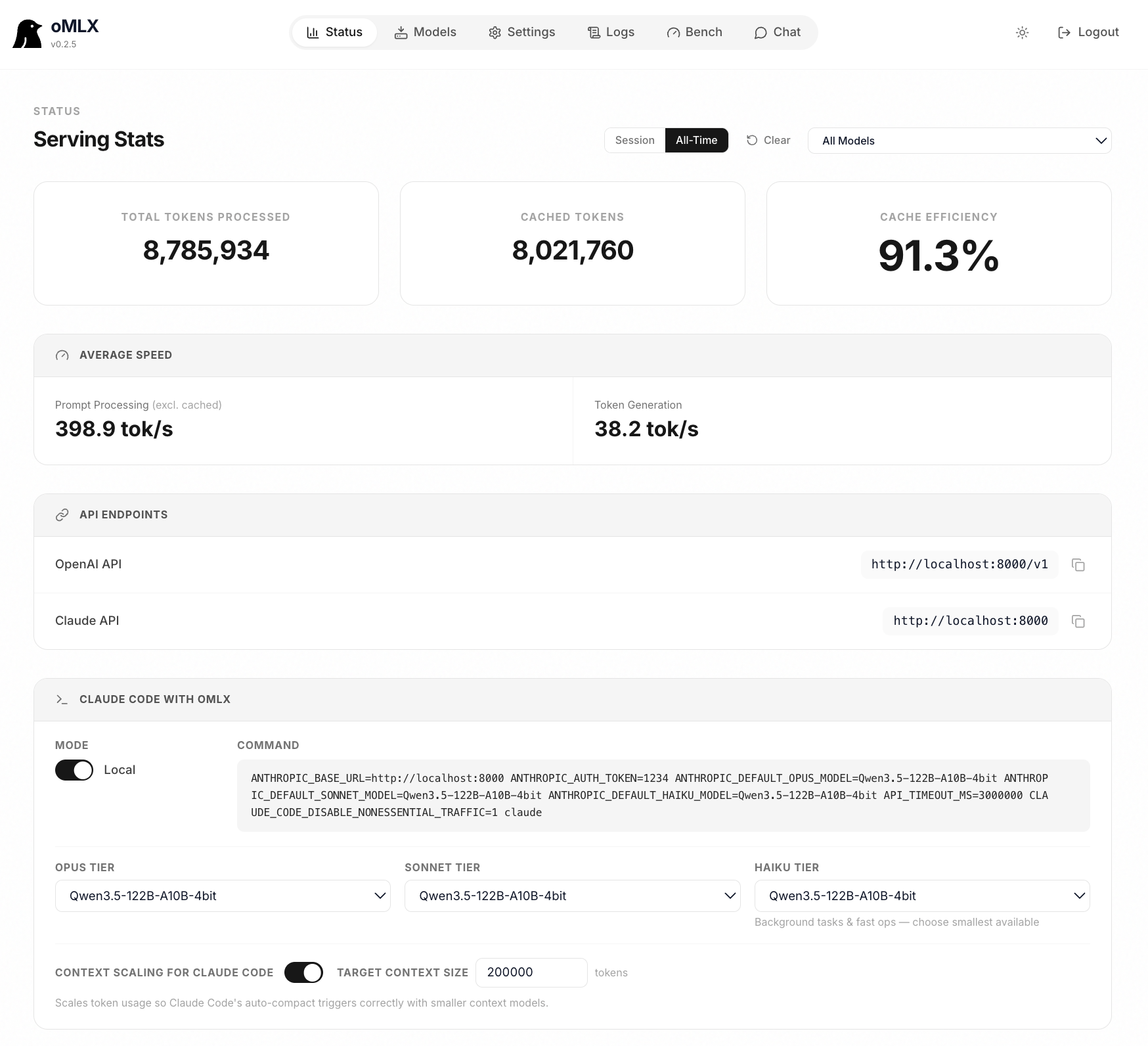
macOS-native MLX server with smart caching. Claude Code, OpenClaw, and Cursor respond in 5 seconds, not 90.
Why oMLX
Coding agents invalidate the KV cache dozens of times per session. oMLX persists every cache block to SSD — so when the agent circles back to a previous prefix, it's restored from disk in milliseconds, not recomputed from scratch.
Performance
All benchmarks on M3 Ultra 512GB. Single request and continuous batching across four popular models.
| Context | Prompt TPS | Token TPS | Peak Mem |
|---|---|---|---|
| 1k | 768 tok/s | 56.6 tok/s | 65.5 GB |
| 8k | 941 tok/s | 54.0 tok/s | 69 GB |
| 16k | 886 tok/s | 48.3 tok/s | 71 GB |
| 32k | 765 tok/s | 42.4 tok/s | 73 GB |
| Batch | Token TPS | Speedup |
|---|---|---|
| 1× | 56.6 tok/s | 1.00× |
| 2× | 92.1 tok/s | 1.63× |
| 4× | 135.1 tok/s | 2.39× |
| 8× | 190.2 tok/s | 3.36× |
| Context | Prompt TPS | Token TPS | Peak Mem |
|---|---|---|---|
| 1k | 1,462 tok/s | 58.7 tok/s | 80 GB |
| 8k | 2,009 tok/s | 54.9 tok/s | 83 GB |
| 16k | 1,896 tok/s | 52.3 tok/s | 83 GB |
| 32k | 1,624 tok/s | 45.1 tok/s | 85 GB |
| Batch | Token TPS | Speedup |
|---|---|---|
| 1× | 58.7 tok/s | 1.00× |
| 2× | 100.5 tok/s | 1.71× |
| 4× | 164.0 tok/s | 2.79× |
| 8× | 243.3 tok/s | 4.14× |
| Context | Prompt TPS | Token TPS | Peak Mem |
|---|---|---|---|
| 1k | 588 tok/s | 34.0 tok/s | 227 GB |
| 4k | 704 tok/s | 30.3 tok/s | 228 GB |
| 8k | 663 tok/s | 26.3 tok/s | 229 GB |
| 32k | 426 tok/s | 14.9 tok/s | 235 GB |
| Batch | Token TPS | Speedup |
|---|---|---|
| 1× | 34.0 tok/s | 1.00× |
| 2× | 49.7 tok/s | 1.46× |
| 4× | 109.8 tok/s | 3.23× |
| 8× | 126.3 tok/s | 3.71× |
| Context | Prompt TPS | Token TPS | Peak Mem |
|---|---|---|---|
| 1k | 187 tok/s | 16.7 tok/s | 392 GB |
| 4k | 180 tok/s | 13.7 tok/s | 394 GB |
| 16k | 117 tok/s | 12.0 tok/s | 403 GB |
| 32k | 78 tok/s | 10.7 tok/s | 415 GB |
| Batch | Token TPS | Speedup |
|---|---|---|
| 1× | 16.7 tok/s | 1.00× |
| 2× | 23.7 tok/s | 1.42× |
| 4× | 47.0 tok/s | 2.81× |
| 8× | 60.3 tok/s | 3.61× |
"The Qwen3.5 models running on oMLX is so fast that it makes running local AI on Mac worthwhile. It is so much faster than LMStudio and the tool calling is so much more reliable."
FAQ
~/.cache/huggingface/hub) shared by Transformers, MLX, vLLM, and llama.cpp, so models you've already pulled just work, no re-download. It also picks up your LM Studio folder and custom directories, and the admin dashboard has a built-in HuggingFace downloader for grabbing new ones.Get started
Download the DMG or install from source. Reads the standard Hugging Face cache and your LM Studio folder, so there's no re-download needed.